
Labelling AI-Generated Content in China
Where the Rules Work and Where They Don't


Executive Summary
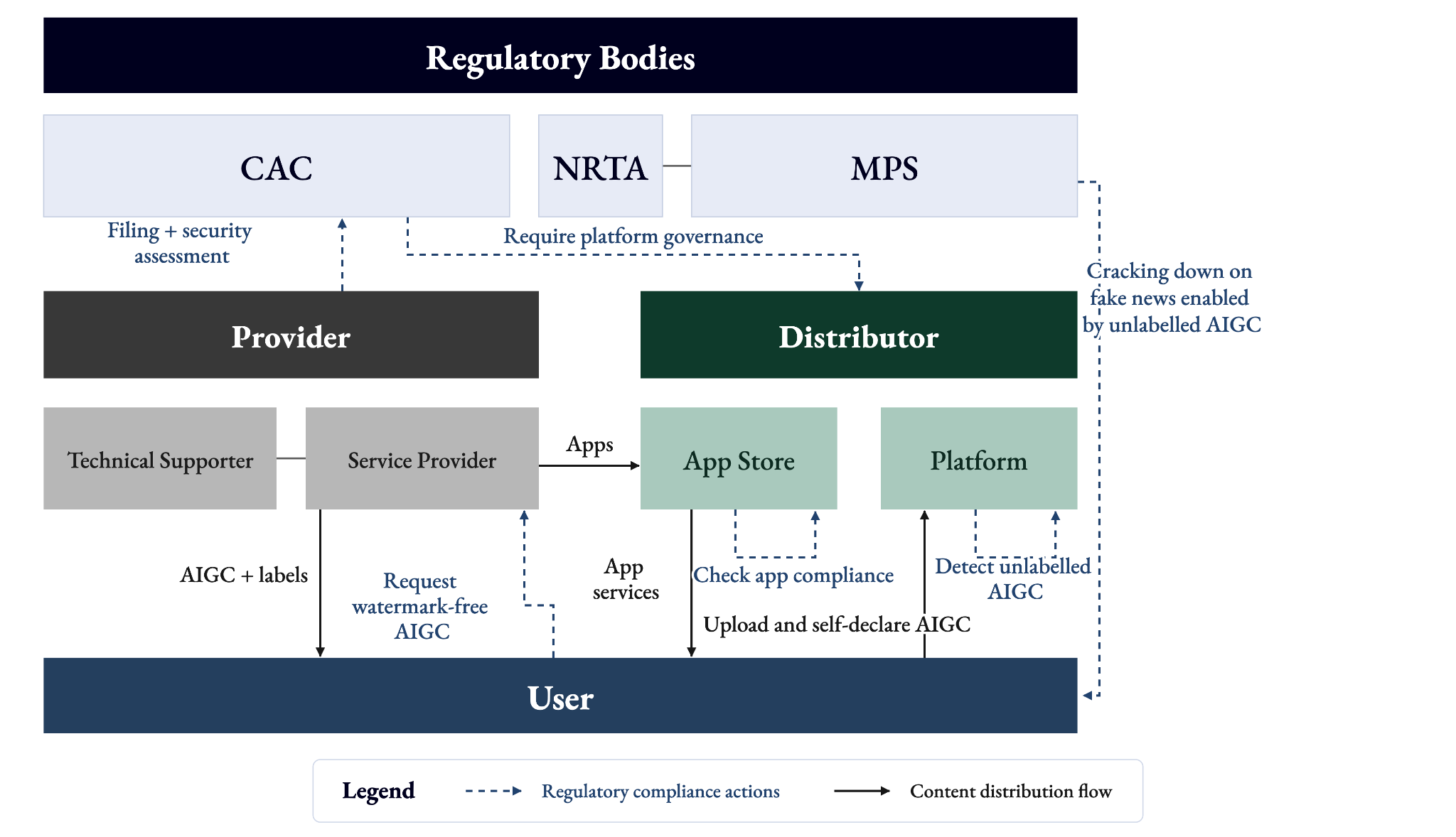
China runs a sophisticated regime for labelling AI-generated content. Developed and updated since 2019, the mandatory and technically quantified frameworks assign a liable party at every layer of the supply chain: model developers, service providers, app stores, distribution platforms, and end users.
Compared with the two other major approaches to content provenance – the EU AI Act’s Article 50 transparency obligations, which take effect from August 2026, and the voluntary C2PA commitments adopted by OpenAI, Google, and other US companies – China’s framework goes further on paper along several dimensions: it is mandatory rather than voluntary, it carries a quantified technical standard, and it names a liable party at every layer of the supply chain. But does this comprehensiveness translate into effectiveness in practice?
Nearly ten months after the most recent AI labelling 2025 Measures took effect on 1 September 2025, the article traces how the measures are enforced and how each liable party has actually behaved. AI service providers label AIGC output, but commercial incentives shape how they do so, with approaches ranging from complying straightforwardly, to monetising watermark-free output as a premium tier, or making overseas-facing services default to no watermark at all. Distributing platforms detect unlabeled AIGC, but unreliably in both directions – unlabelled AI videos still circulate on major platforms even after successive enforcement campaigns, while human creators are wrongly flagged as AI. Users declare whether they use AI to generate content, but a thriving ecosystem of watermark-removal tools and techniques serves those who would rather not.
China’s regime serves as a useful stress test for the field of content provenance, with its ten months of enforcement yielding three lessons. First, the actual experience of the labelling framework is shaped as much by state mandate as by the localised business calculus of individual platforms, a dynamic that illustrates how China’s AI regulation functions as a network of semi-autonomous governance units with bounded agency. Second, enforcement shows that AI governance increasingly needs both policy and technical solutions. Pairing the 2025 Measures with a mandatory technical standard closed the policy-technical loop at the rule-making layer, but the same alignment problem recurs unsolved at the downstream. Third, along an increasingly branched supply chain, compliance is a spectrum rather than a binary – what regulators actually police is whether non-compliance stays within a tolerable range, with recurring campaigns doing the work of deterrence that regulations on paper cannot yet do.
The Formation of the System: Regulations in Brief
China’s framework for labelling AI-generated content accumulated over six years through three successive instruments. Each broadened scope and tightened technical demands, but all three were animated by the same foundational concern: that synthetic content would circulate as authentic and deceive the public.
The first instrument was the 2019 Provisions on the Administration of Network Audio-Video Information Services (《网络音视频信息服务管理规定》, referred to as A/V regulation below), jointly issued by the Cyberspace Administration of China (CAC), the Ministry of Culture and Tourism (MCT), and the National Radio and Television Administration (NRTA), and effective 1 January 2020. Article 11 required “prominent labelling” (显著标识) of non-authentic audio-video content produced or disseminated using deep learning or virtual reality, and prohibited the use of these technologies to spread fake news. Coverage was confined to the audio-video channel, and the regulation did not detail a technical standard for what “prominent” meant in practice.
The 2021 Provisions on the Management of Algorithmic Recommendations in Internet Information Services (《互联网信息服务算法推荐管理规定》, referred to as Algorithmic Recommendation Provisions below), issued by CAC together with three other departments and effective 1 March 2022, was not itself a labelling regulation, but it carried the enforcement one step further by placing parts of the responsibility on platforms. Article 9 required algorithmic recommendation service providers to maintain a feature library for identifying illegal and undesirable information, and specified that upon discovering algorithm-generated synthetic information without a prominent label, the provider must add one before continuing transmission.
The 2022 Provisions on the Administration of Deep Synthesis in Internet Information Services (《互联网信息服务深度合成管理规定》, referred to as Deep Synthesis Regulation below), jointly issued by CAC, the Ministry of Industry and Information Technology (MIIT), and the Ministry of Public Security (MPS), and effective 10 January 2023, expanded coverage to text, image, audio, video, and virtual scenes, and replaced named-technology definitions with a six-category taxonomy (Article 23). They introduced the two-tier labelling architecture that all subsequent instruments build on: implicit labels (technical markings not perceptible to users, Article 16) and explicit labels (visible markers required where public confusion is likely (Article 17).
The 2025 Measures for Labelling AI-Generated Synthetic Content (《人工智能生成合成内容标识办法》, referred to as the Labelling Measures below), jointly issued by CAC, MIIT, MPS, and NRTA and effective 1 September 2025, dropped technology-specific framing entirely. AIGC is now simply “information generated or synthesised using AI technology” (Article 3). The measures further specified both explicit-label placement and implicit label content. The accompanying national standard GB 45438-2025 (网络安全技术 人工智能生成合成内容标识方法) – the first mandatory national standard on AI – further sets quantified explicit-label specifications such as the width of the watermark image and prescribes the technical method for embedding that metadata across file formats. The obligation chain extends from technical supporters and service providers through app stores to distribution platforms, which must detect and label three categories of content: confirmed AIGC (metadata present), user-declared AIGC (no metadata, user self-disclosed), and suspected AIGC (no metadata or declaration, but platform detection identifies synthetic traces). Users are obligated to self-declare their use of AI at the point of publication.
The 2022 Deep Synthesis Regulation establishes the foundational, principle-based labelling obligation. In contrast, the 2025 Labelling Measures and accompanied national standard do not supersede or replace those provisions but serve as the implementing rules that supply specific, enforceable technical standards, aiming to transform broad legal principles into measurable technical compliance. Officials have characterized it as a transition from “principle-based rule of law (原则法治)” to “technology-enforced rule of law (技术法治)”.
Meanwhile, the 2019 A/V regulation continues to apply to audio-video scenarios not fully covered by the 2025 Labelling Measures, retaining independent normative force in those areas. Similarly, the 2021 Algorithmic Recommendation Provisions remain in force and govern a broader range of algorithmic governance issues beyond content labelling.
The Enforcement of the System: How does labelling (not) work
Rules on paper are one thing, while actually putting them into action is another. This section traces how each actor in the chain should have behaved and has actually behaved: the regulators who enforce rules, the providers who label, the distributors who detect, and the users who self-report.
I. Regulatory Bodies: Managing AIGC
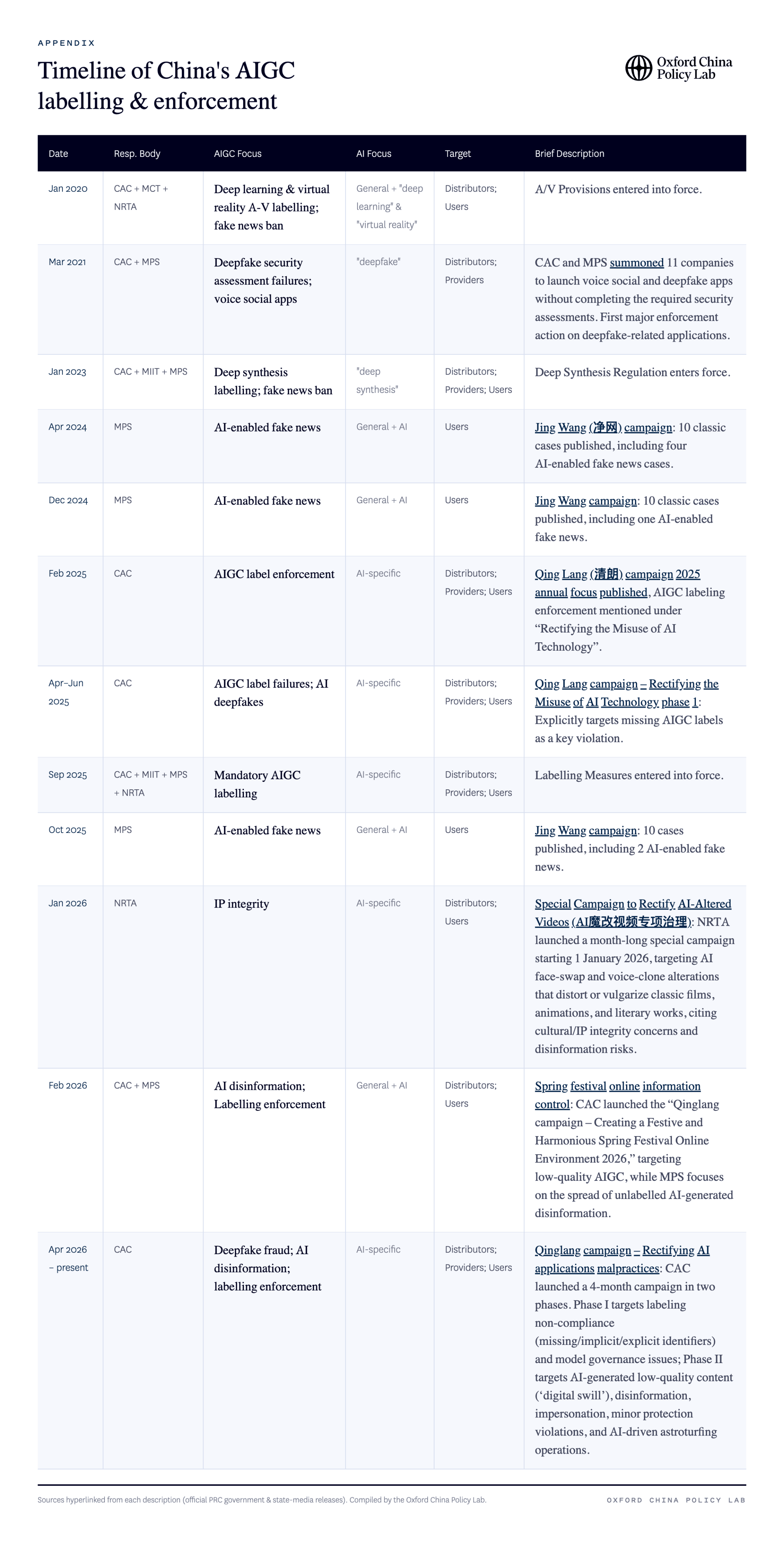
To date, there are several streams of active enforcement actions following the first AIGC measures issued in 2019. Among these enforcement actions, CAC and MPS emerged as the leading bodies to regulate AIGC providers (technical supporters and service providers), users, and distributors (platforms and app stores).
Across campaigns, CAC appears to be mainly focused on the regulation of providers and distributors on technical compliance through its 清朗 (qing lang, “clean and bright”) action series: mainly, making sure that technical supporters and service providers went through the related AI registry and security assessment (see China’s AI Services Registry System, A Complete Guide for more), detecting unlabelled services and ordering app stores and social media platforms to remove them, while also crack down on grey services that help people removing related AI labels.
Meanwhile, MPS focuses more on the users’ front and legal liability of fake news through the 净网 (jing wang, “cleaning the web”) action series, including issuing warnings, summoning individuals, and issuing penalties to those who use AI to produce misinformation and fake news. Although not directly enforcing AI labelling, the crackdown on unlabelled AI-enabled fake news is also an important part of the enforcement stream.
Despite their somewhat separate focuses, the exact coordination and case referral mechanism between CAC and MPS remains unclear. Research from MPS has also noted that overlapping mandates between the two bodies introduce some ambiguity at the enforcement margins.
In addition, the National Radio and Television Administration (NRTA), a co-issuer of the 2025 Labelling Measures, plays a dual role when it comes to AIGC, focusing on both development and regulation, though the regulation arm is relatively thin compared to CAC and MPS. It has cracked down on AI alteration of classic film and television content, while simultaneously hosting annual AI content creation competitions and co-producing AIGC training campaigns with major platforms
See the Appendix for the enforcement timeline.
II. Providers: Labelling AIGC
Under China’s AI labelling framework, providers1 carry the most extensive and layered set of obligations. This includes both service providers (服务提供者), whose primary job is to offer services that use AI, and technology supporters (技术支持者), who develop the underlying models and systems.2 Before any public-facing AI service can launch, providers must complete a mandatory filing process with the CAC. We detail this process in our piece, China’s AI Services Registry System, A Complete Guide.
Providers bear the primary obligation to label all AI-generated content at the point of generation. The 2025 Labelling Measures establish two distinct types of label. Explicit labels resemble “watermarks”–visible indicators (text, graphics, or audio cues) placed at specified positions depending on the content type, designed to be immediately perceptible to users. It is a conditional obligation under the framework and applies only to AI-generated content that may cause public confusion or misunderstanding – although what counts as confusing is not clearly defined. Implicit labels, by contrast, are metadata embedded in the file’s metadata and not visible to users, containing the provider’s name or code, a content identification number, and information about the content’s generative origin. Unlike explicit labels, implicit labelling is a universal, unconditional obligation that applies to all AI-generated synthetic content, regardless of whether it might confuse the public. Even when users request watermark‑free output–an exemption that removes explicit labels for legitimate professional or commercial use–implicit labels must remain intact in the file metadata. The two tiers thus serve complementary but asymmetrical functions: explicit labels target user‑facing deception where confusion risk exists, while implicit labels create a verifiable chain of provenance that applies across the entire universe of AIGC, aiming to provide a technical backbone that platforms and authorities can check independently.
Providers are also required to share labelling information with authorities to support enforcement, and must retain logs of all content produced, including in cases where a user has requested content without explicit labels – under Article 9 of the 2025 measures, users can request watermark-free output from the providers for reasons like some commercial or professional use cases. For example, an artist who uses AI to create digital artwork may not want a big watermark even if they are willing to disclose the use of AI. Technical supporters must conduct their own security assessments, manage training data responsibly, and, where their tools enable face or voice editing, obtain separate consent from the person whose likeness is edited.
Together, these requirements position providers as the primary technical accountability layer in the regulatory chain.
Enforcement status:
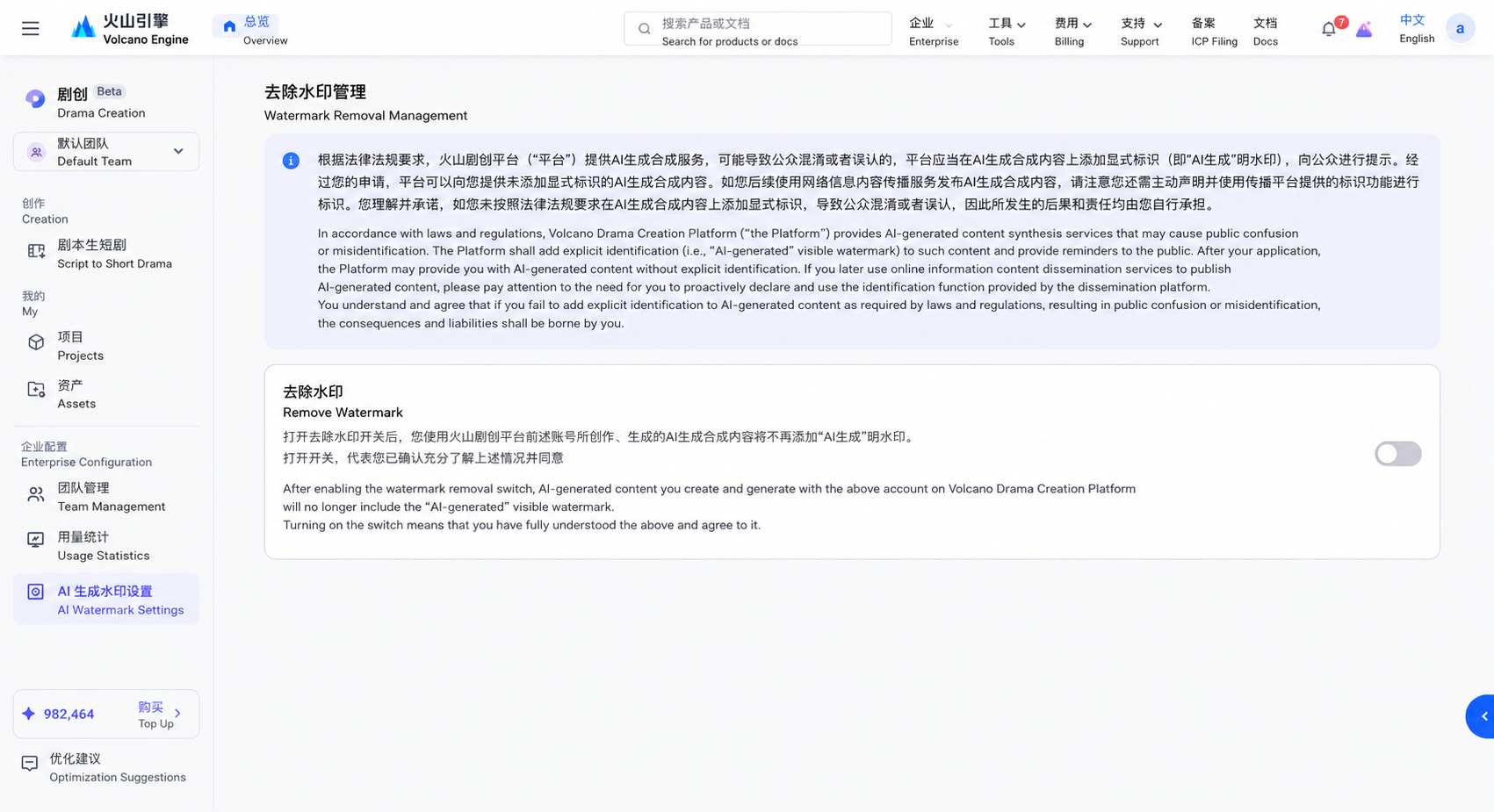
In practice, providers balance regulatory compliance with business incentives. While watermarks serve as product branding, users often prefer watermark-free content for professional or commercial projects. Under Article 9, providers can offer watermark-free output provided they establish clear usage agreements and retain usage logs.
These competing pressures produce a spectrum of watermarking practices. For example, ByteDance’s Dramart (火山剧创平台), Volcengine’s service for AIGC short videos, adopts a direct approach to compliance by directing its users toward a watermark-free option that includes a clear explanation of the regulatory requirements, which ensures that the user is explicitly informed about the underlying legal framework governing the content. However, Dreamina (即梦AI), an image and video generation service also by ByteDance, opts for a premium system of watermarking, giving free users watermarked content and premium paid users watermark-free ones. Meanwhile, ByteDance’s overseas-facing service Seedance 2.0, which does not need to comply with China’s regulations, chooses to set watermark-free output as the default – which remains accessible to Chinese users through VPNs.
III. Distributors: Detecting AIGC
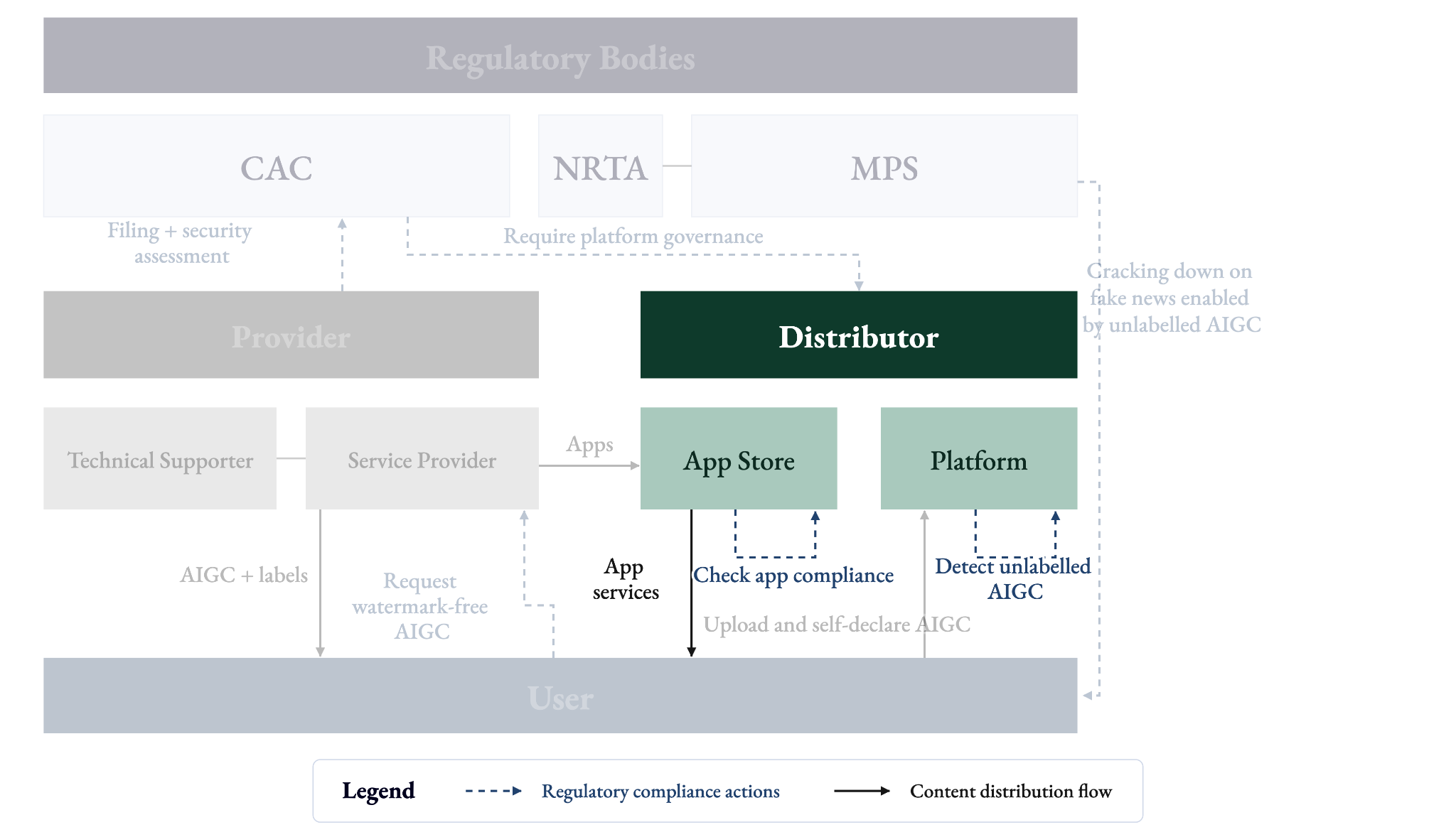
Under the 2025 Labelling Measures, which came into force on 1 September 2025, distributors operate as the last line of labelling defence. App stores form the first layer of such defence. Before onboarding any application, they must require providers to declare whether it offers AI generation services and verify labelling compliance materials. In theory, every app a user downloads has been verified, so all AIGC reaching platforms arrives already labelled. Users, either getting AIGC directly from providers (e.g., generate an image from Qwen) or specific apps, then upload it to the platform to share.
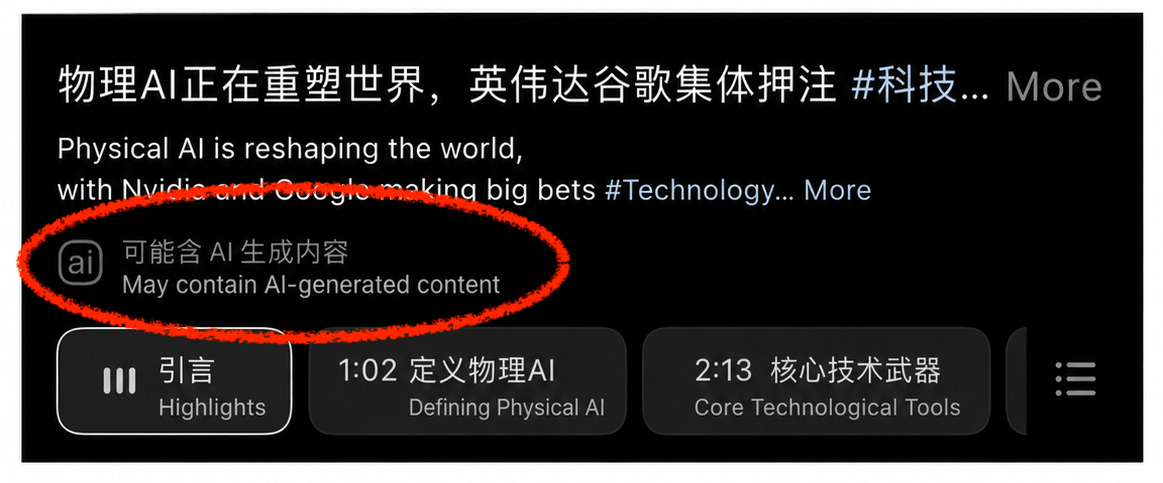
Platforms, as the second layer, must actively detect AIGC and add visible labels to three categories of content: confirmed AIGC (embedded metadata present), user-declared AIGC (no metadata, but user has self-disclosed), and suspected AIGC (no metadata or declaration, but the platform’s own detection identifies synthetic traces). Moreover, platforms are required to provide users a self-declaration option when uploading AIGC to the platform. If users fail to self‑declare, platforms impose internal sanctions based on their user agreements and community guidelines. For instance, Rednote warns that unlabeled AIGC will be subject to restricted content distribution, and repeat or severe violations may lead to account suspension or banning.
After the 2025 labelling measures took effect, major platforms updated their user agreements and announced compliance rollouts. The compliance posture was, on paper, comprehensive. However, platform detection fails in two directions: false negatives – unable to detect unlabelled AIGC – and false positives – wrongly marking human-made content as AIGC. Both bear implications that threaten the platform information ecosystem.
Enforcement status:
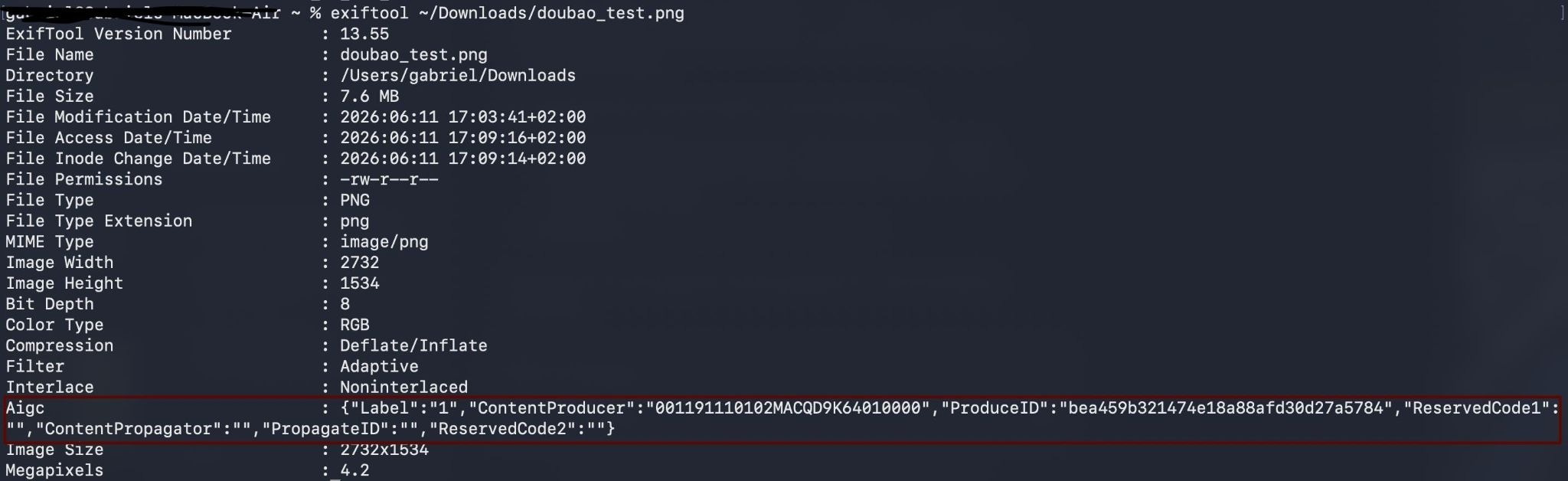
Supposedly, even if users do not declare using AI, platforms can spot AIGC through the implicit metadata the provider embedded in the file. In practice, the metadata layer is fragile. A screenshot, format conversion, re-export through editing software, or re-upload across platforms can strip the metadata entirely (see IV for more details). For content without metadata, watermarks, or self-declaration, platforms fall back on classifiers and human review.
As one technical solution, classifiers, automated models trained to distinguish AI-generated content from human-made content, are insufficient. Researchers note that such classifiers perform poorly on content outside their training distribution and can carry higher false-positive rates for certain groups, and because they rely on differences between machine and human output that may shrink as models improve, they require continuous retraining and recalibration just to stay viable. Hybrid content is even harder. When AI edits are confined to part of an otherwise authentic image, commercial detectors that scored 91% on fully-AI imagery drop to 55%.
While Rednote claimed to have a “huge human reviewer group” to catch what machines miss and establish layered defence, the actual enforcement reality suggests otherwise. In February 2026, after CAC’s first attempt to urge platforms to regulate unlabelled AIGC, a researcher from ChinaTalk found that many AI-generated videos on Rednote were still unlabelled, noting that real-life images with AI edits make the situation more difficult. To put the scale in perspective, Rednote alone receives over 9 million daily posts; across the entire Chinese internet, daily video uploads exceed 130 million. Meanwhile, a CAC enforcement campaign reported to clear 960,000 pieces of problematic content in two months (including but not limited to unlabelled AIGC), which barely scratches the surface of what gets uploaded in a single day. As of early June, after the start of yet another Qinglang campaign that explicitly regulates AI applications, including labelling, the author still found many clearly AI-generated videos on WeChat video channels and Rednote unlabeled.
Besides false negatives that allow certain fake news to proliferate, false positives – wrongly accusing human-made content as AI generation – also appear to be a common issue. False positives can create chilling effects and frustrations that, in turn, prompt users to explore ways to not be marked as AIGC, which can contribute to more evasion techniques. This is currently prevalent in the detection of AI writing and AI-generated digital art. For example, many Rednote and Weibo users complain about being wrongly flagged as using AI to produce content when actually writing the text themselves following certain “popular” templates. Meanwhile, digital arts creators on platforms also constantly struggle with their work being flagged as “may contain AI”, to the extent that livestreaming to prove the work is human became a phenomenon (see more in the upcoming ChinaTalk article).
Moreover, besides tackling AIGC to prevent deepfake and disinformation according to the state’s mandate, certain platforms also have a distinct reason to crack down on AIGC– the gray market of “AI-operated accounts (AI托管账号)”. With the proliferation of AI agents, some accounts on social media platforms have already fully automated, using AI to register, publish, and interact with other human users (or maybe other AI). More community-oriented platforms like Rednote view the automation of interaction as fundamentally contradictory to its idea of human connections, thus taking a more proactive approach to regulate AIGC. It published an AI governance proposal, which encourages AI as a creativity tool and against using it to create disinformation and low-quality content. It also reiterates that users need to label AIGC. From January to April, Rednote alone handled over one million instances of AI-related misconduct, including over 800,000 AI-managed accounts and nearly 150,000 AI-generated fake posts. While the proactive approach does put Rednote at the AIGC governance frontier, false negatives and false positives in detection still make the process more complicated.
IV. Users: Self-Reporting AIGC
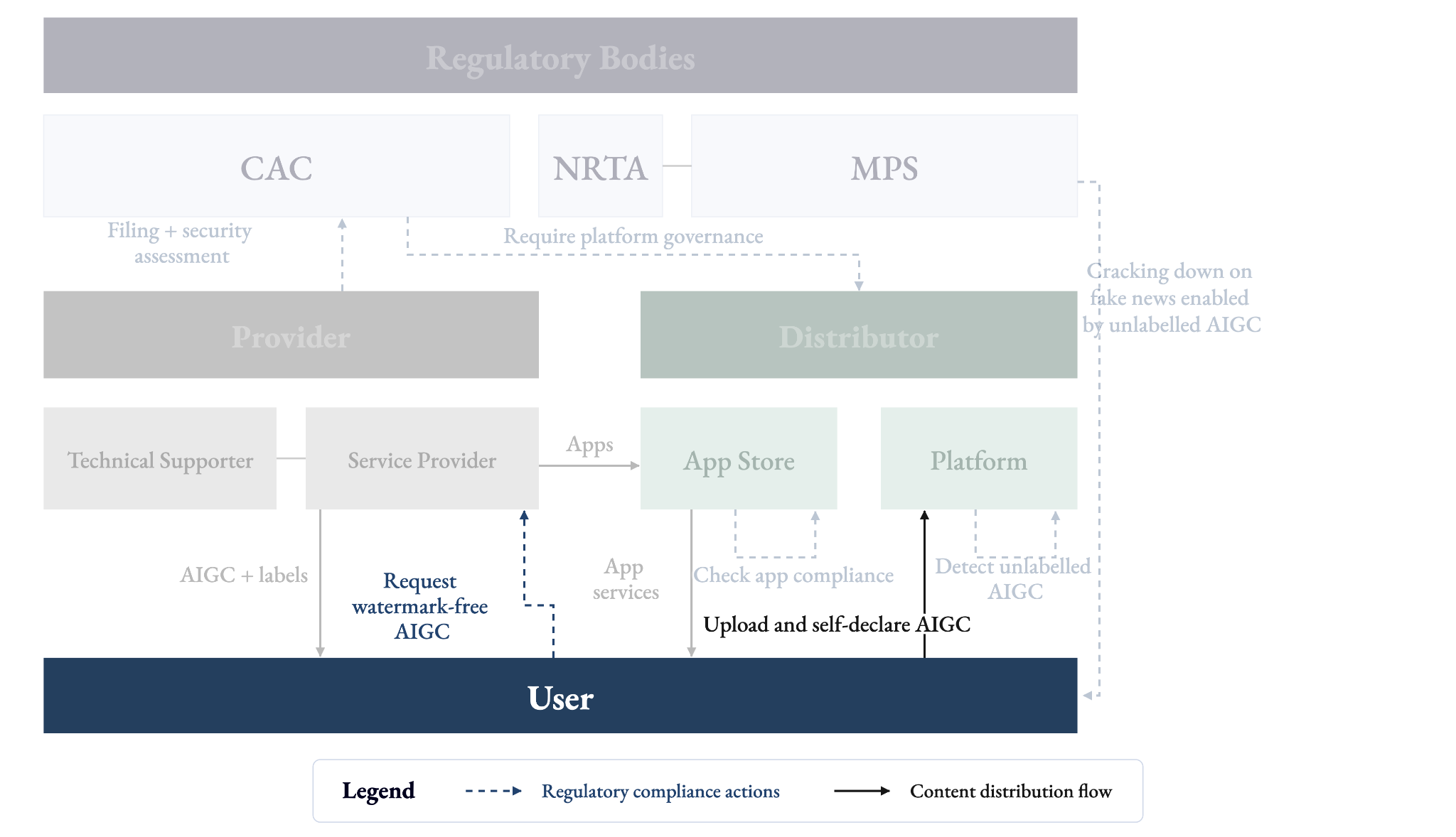
Under the 2025 Labelling Measures, users who publish AI-generated content are required to actively declare and label it using the platform’s own labelling function. This is an independent obligation that runs parallel to, and does not substitute for, the platform’s detection duties.

The 2025 Measures also introduce one formally sanctioned route by which users may receive content without explicit labels. Users may request AI-generated content without the visible label, and the provider may comply, but only after establishing the user’s labelling obligations and use responsibilities through a user agreement, and retaining logs of the provision for at least six months.3 Crucially, this is an exemption from explicit labelling only, and implicit labels embedded in the file metadata remain mandatory regardless.
Enforcement status:
In an ideal scenario, even if users do not self-declare the use of AI – which itself violates the regulation – others can still spot it through watermarks while the platform detects it through embedded metadata. However, users have strong incentives to remove both layers: the watermark, so the public does not see it, and the metadata, so the platform does not flag it. For instance, one might want to make disinformation seem real or to make AI artwork not be seen as mechanical and not original. Meanwhile, getting watermark-free AIGC might either be too costly under a watermark freemium system or too complicated (see III).
Plenty of tools exist to help users cheat the system. Many public tools are available in China or beyond to strip the full range of explicit watermarks of AI-generated images or videos without sending requests to the providers – both as open source projects on GitHub and paid services on Taobao.4 People also found out that “AI watermark removal” services provided by AI companies can remove the explicit watermarks these companies put on their AI-generated images, or that changing downloading methods can access a watermark-free image, whether by design or oversight.
Stripping metadata is equally accessible through technical means. Simple interventions work for images. One can easily remove metadata by taking a screenshot or using editing software. More robust techniques – regeneration attacks that reconstruct content to eliminate embedded signals, adversarial perturbations, and even JPEG compression at sufficient strength – can degrade or destroy invisible content-level watermarks while preserving apparent visual quality. Detection research shows the same fragility, with AI detectors trained to spot images generated by one model can lose up to 40 percentage points of accuracy when faced with newer, unfamiliar AI models, and that accuracy drops even further once the image has been compressed or otherwise altered. Thus, while the implicit label is meant to be the technical backbone of the entire system, in practice, it only holds up as long as no one along the way decides to strip it.
Implication for AI Governance
As the executive summary noted, China’s system is possibly the most comprehensive of the three major content-provenance approaches on paper, as it is mandatory, quantified, and supply-chain-wide. The experience over the past ten months offers useful insights into the case of content provenance in the age of AI.
Content provenance is a hard problem everywhere, and the realistic goal should not be perfect detection, but rather curbing proliferation enough to preserve trust. China’s labelling system is missing a basic metric: a measurable, in-force standard for how well platforms must detect AI-generated content already in circulation. The regulator has issued a non-binding practice guidance (实践指南)5, which does address content detection in an attempt to standardise the practice, but the guidance itself remains notably vague.6
This gap is not unique to China. GB 45438-2025 quantifies labelling requirements but not detection accuracy, and C2PA is, by design, a marking specification rather than a detection one. The EU comes closest, with its Code of Practice on Article 50 introducing concepts of error rates, false-positive risks, and robustness to content alterations across distribution channels — though without specifying numerical thresholds. The underlying technical problem compounds the regulatory one: as generative models grow more sophisticated and spread across more domains of content creation, detection itself becomes harder to perform, as does defining a meaningful accuracy standard in the first place.
Achieving full accuracy is likely infeasible regardless of how granular the labelling rules are or how widely responsibility is distributed across the content supply chain, and enforcement that chases full accuracy can drift toward two failure modes: a chilling effect on human creators wrongly flagged as AI, and unlabelled AI content that continues to circulate freely. Perhaps, then, the more realistic goal is not 100% accuracy but a tolerable threshold: a level of AI-enabled disinformation low enough to preserve public trust, adjustable through periodic enforcement campaigns rather than fixed by a permanent technical standard.
Platforms have become semi-independent AI governance regimes. The effective labelling regime a user encounters is set less by the Labelling Measures than by each platform’s business calculus. Rednote’s enforcement is arguably well beyond the state mandate – over one million AI-misconduct cases handled in four months, plus its own published governance proposal – because automated content threatens the human connection the platform’s community runs on. Platforms whose revenue follows traffic volume may face the opposite incentive and tolerate more synthetic content. Nor is this fragmentation unique to platforms: China’s AI regulation, in practice, operates as multiple semi-independent governance units. The AI service registries, for instance, rely on assessments run by provincial CACs that differ in rigour. As AI agents further complicate the supply chain and infrastructure of AI, more such units exercising bounded agency are likely to emerge – a dynamic we will return to in future pieces in this series.
Enforcement is both a technical question and a policy question. The clearest signal of this principle was the release of the 2025 Labelling Measures together with an accompanying mandatory standard, a move that resolves “the longstanding issue of misalignment between management regulations and technical standards in past governance efforts”, according to Geopolitechs, a Substack specialized in China’s AI regulation. The “measures + standards” bundle is viewed as a governance closed-loop, in which institutional directives and technical implementation reinforce each other. But the enforcement record shows that closing the loop at the rule-making layer is not enough: the same policy-technical alignment problem recurs at every downstream layer of the supply chain, where no equivalent bundle exists. Detection illustrates the point. On the policy side, platforms need “machine + human” review systems in which human reviewers catch false negatives and adjudicate complaints about false positives. On the technical side, detection accuracy, metadata traceability, and watermark durability all need substantial improvement. Neither strategy effectively addresses the underlying issue, and the two failure modes are mutually reinforcing: false positives drive the demand for evasion tools, and these tools further undermine detection accuracy.
Enforceability is unevenly distributed along an increasingly complicated AI supply chain, and compliance is a spectrum rather than a binary. It might have been easier, years ago, to picture the AI supply chain as a simple line from model provider to end user. Today, as each sector within AI grows and specialises and more actors participate, the chain has lengthened and branched. This piece has traced at least four officially recognised nodes in AIGC’s chain, each further split into smaller categories – and beyond the visible participants, external ecosystems are increasingly entangled in it, notably open platforms like Taobao and GitHub that host labelling-removal tools and services. Each node has its own incentives to comply or evade, and both enforcement and compliance run along a spectrum of over- and underperformance. The obligation to “detect AIGC” is a range of success rates, not a yes or no; some providers offer watermark-free services in more compliant ways than others. The core of enforcement is therefore not box-checking but judging whether the degree of compliance falls within a tolerable range. When labelling’s false rates sit within some threshold, regulators may take no action despite visible evasion services and partial non-compliance – but the recurring CAC and MPS campaigns serve as a reminder that the regulator is watching, effectively discouraging suspicious practices.
The question that China’s labelling system alone cannot answer, however, is how to handle the cross-border movement of content. Even if every provider in China complied perfectly, Chinese users can generate content through overseas tools – including Chinese providers’ own overseas services, such as Seedance 2.0, which defaults to watermark-free output – and circulate it back into the Chinese internet. Closing that gap would likely require international coordination on provenance standards, as no single jurisdiction can alone govern AIGC, which is naturally cross-border in its generation and transmission.
Zilan Qian
Research Associate, Oxford China Policy Lab
Acknowledgements:
Zilan is grateful to Gabriel Wagner, Nick Corvino, Matt Sheehan, Sophie Zhuang, and Alan Chan for their feedback on earlier drafts, and to Kayla Blomquist and Karuna Nandkumar for their insights and editorial support in developing this research.
Although in some contexts, actors that provide AIGC services are also referred to as "the platform", here we use provider to emphasize their role in providing services. Meanwhile, "platform" refers to a space that distributes AIGC content, such as social media platforms
In reality, the line between the two is somewhat blurry. DeepSeek can be both a technical supporter to other AI service providers by offering the foundational models for their products, and a service provider itself by offering web and API services to users.
The regulation does not mandate any pricing model for such watermark‑free output. However, in practice, some providers have treated the exemption as a commercial opportunity: for instance, offering watermark‑free content as a paid premium feature (e.g., Dreamina gives free users watermarked outputs while paid subscribers can obtain unlabelled versions), or simply accommodating user demand for more aesthetically appealing products. These are observed market practices, not statutory requirements, and the extent to which providers profit from Article 9 remains speculative.
Practice guidance typically elaborates on the national standard with more detailed technical examples.
 | A guest post by
|